
Scenariusz
porządek najlepiej zaczynać od redukcji. niby trywializm, a jednak często widzę, że osoby próbują najpierw 'porządkować’ a zapominają o tym pierwszym kroq – a przecież łatwiej jest uporządkować np. 1oo elementów, niż 2oo. w przypadq subskrypcji nie jest inaczej – wiele pozostaje bez właściciela (co było poprzednio) ale też wiele pozostaje pustych. w ramach pojedynczego tenanta subskrypcje pochodzą z różnych offeringów i największy bałagan jest z developerskimi wynalazkami z MSDN, MSDN Dev/Test, Trial czy Visual Studio, które mogą sobie powoływać na żądanie.
aby wyłączyć tą możliwość należy założyć ticket do wsparcia. nie ma samodzielnej metody kontroli. jedyne, co można zrobić samemu, to zdefiniować domyślną Management Group do której (wszystkie) subskrypcje będą wpadać. dzięki temu 'nasze’, z głównej umowy typu Enterprise czy MCA zakładamy tam, gdzie mają być, a pozostałe, z niewiadomych źródeł, można zautomatyzować – czy to polisami czy jakimś triggerem.
Czysty PowerShell
napisanie prostego skrypciq w PS, który przeliczy ilość zasobów i ładnie wyświetli listę, nie jest skomplikowane:
$subscriptions = Get-AzSubscription | ? state -ne 'disabled'
$counts = @()
foreach($sub in $subscriptions){
write-host "processing $($sub.name)..." -ForegroundColor grey
try {
Set-AzContext -SubscriptionObject $sub | Out-Null
} catch {
write-host "error accessing $($sub.Name)" -ForegroundColor Red
$counts += [pscustomobject]@{
subscriptionName = $sub.Name
subscriptionId = $sub.Id
resourceCount = -1
}
continue
}
$res = Get-AzResource
$counts += [pscustomobject]@{
subscriptionName = $sub.Name
subscriptionId = $sub.Id
resourceCount = $res.count
}
}
$counts | sort resourceCount | export-csv -nti c:\temp\ResourcePerSubscription.csv -Encoding utf8
&(convert-CSV2XLS C:\temp\ResourcePerSubscription.csv)
nie lubię one-linerów, lubię wiedzieć co się dzieje, i mieć kontrolę – dla tego skrypt może wydawać się niepotrzebnie rozbudowany… ale mi zajmuje ok 1o min żeby taki napisać, wszystko widzę, jak coś wywali to wiem gdzie, mogę to debugować – i koniec-końców czas zainwestowany w trochę więcej więcej kodu i jakąś podstawową obsługę błędu – zwraca mi się dość szybko. zwłaszcza, że pojedynczy przebieg takiego kodu może trwać całkiem sporo – w moim przypadq to ok. 10 minut….
Przyspieszamy
… i właśnie ten czas jest denerwujący. oczywiście – niby takie rzeczy robi się bardzo rzadko, więc optymalizacja jest trochę sztuką-dla-sztuki. dla mnie jest sztuką-dla-nauki. języki operujące na zbiorach danych – jak SQL czy KQL – nie są dla mnie codziennością. warto się więc pogimnastykować, bo to z kolei zwróci się w przyszłości. tak było w przypadq samego PS – przedstawiony wcześniej skrypt, kilka lat temu, pewnie zająłby mi kilka razy więcej czasu. dziś z automatu wiem gdzie wrzucić obsługę błędu, a gdzie to jest strata czasu, kiedy warto zainwestować więcej, a kiedy walnąć one-liner’a.
spróbujmy więc uzyskać podobny efekt korzystając z KQL. największym problem dla myślących proceduralnie czy sekwencyjnie, jest przestawienie głowy na pracę na zbiorach. dobrze jest sobie zrobić powtórkę z matematyki, w ramach gimnastyki zwojów.
na początq szkielet, którego używam jako starter, i zmieniam sobie tylko kwerkę:
$searchParams=@{
first = 1000
query = $QUERY
}
$allResults = @()
do {
$results = Search-AzGraph @searchParams
$results|%{$allResults+=$_}
$searchParams.ContainsKey('skip') ? ($searchParams.skip+=1000) : $searchParams.add('skip',1000)
} while($results.skipToken)
$allResults
tak rozbudowany zapewnia, że jeśli przekroczy się limit 1.ooo odpowiedzi, zostanie ładnie obsłużone. warto sobie jakiś-taki szablon trzymać. teraz będę rozbudowywał swoje $QUERY, żeby uzyskać pożądany efekt.
#1
najpierw prosty test:
$QUERY = "resources
| summarize nrOfResources=count() by subscriptionId"
ten przykład zwraca ładnie wyniki – ilość subskrypcji wraz z ilością zasobów. to czego jednak NIE zwraca, to nazwy subskrypcji – a nam, humanoidom, jednak łatwiej posługiwać się literkami niż GUIDami. po drugie nie ma subskrypcji pustych. wynika to z faktu, że zapytanie jest do 'zbiór zasobów’ a potem grupuje je po atrybucie 'subscriptionId’. więc jeśli subskrypcja nie ma zasobów to nie ma zasobów do zaraportowania subskrypcji…
#2
ponieważ wynik ma być częścią wspólną zbioru subskrypcji oraz zbioru zasobów, najpierw napiszmy obie strony zapytania…
jako ciekawostka – jest pewna niespójność dotycząca zasobu/resource. chodzi o subskrypcje i ResourceGroupy, które zasadniczo, z definicji, nie są zasobami, a kontenerami zasobów. przez to mają swoją oddzielną domenę nazewniczą 'resourceContainers’. czemu niespójność? bo przy niektórych operacjach i commandletach traktuje się je jako zasoby. spojrzyj na samo zapytanie: ResourceContainers z microsoft.resources/subscriptions ?
…a że prawą stronę praktycznie napisaliśmy wcześniej, bo to po prostu zapytanie o zasoby, zajmijmy się lewą stroną:
$QUERY = "resourceContainers
| where type =~ 'microsoft.resources/subscriptions'
| project subscriptionId, subName=name"
w zbiorze subskrypcji, elementy mają już pełne informacje, czyli np. atrybut 'name’ – w ten sposób można wyciągnąć nazwę subskrypcji.
porównanie niewrażliwe na wielkość znaków '=~’ jest bezpieczniejszym sposobem niż '==’. należy na to bardzo uważać, ponieważ KQL jest wrażliwy na wielkość znaków w atrybutach czy nazwach, zapisywanych
camelBack’iem a inne narzędzia pokazują je CamelCapsem. jeśli więc nie dostajesz wyników, zacznij od sprawdzenia wielkości znaqw, albo użyj [bardziej kosztownego] '=~’ .
mamy więc oba potrzebne zbiory – wszystkie subskrypcje oraz wszystkie zasoby. trzeba teraz wyciągnąć odpowiednio skonstruowaną część wspólną…
#3
do różnych operacji łączenia zbiorów służy, co dość oczywiste, 'join’. problem w tym, że jest wiele różnych joinów, a przypadq Kusto jest ich wyjątkowo dużo.
KQL – to Kusto Query Language. czasem łatwiej coś wyszukać korzystając z tego słowa kluczowego… przynajmniej póki search nie jest podpięty pod GPT (;
co więcej, domyślnym operatorem, jest [nomen-omen] unikalny dla KQL innerunique. to może być dość istotna różnica, więc może warto dodawać zawsze odmianę? tu na leniucha:
$QUERY = "resourceContainers
| where type =~ 'microsoft.resources/subscriptions'
| project subscriptionId, subName=name
| join resources on subscriptionId
| summarize nrOfResources=count() by subscriptionId,subName
| sort by nrOfResources asc"
jeśli odrobiłe(a)ś lekcję ze zbiorów, to powinno być łatwe: wyszuqjemy wszystkie subskrypcje i wyciągamy z niego ID i nazwę [project] następnie bierzemy wszystkie zasoby i wyciągamy część wspólną, korzystając z kolumny subscriptionId. następnie liczymy ilość zasobów [summarize] i sortujemy po ich ilości wzrastająco. brzmi jak bajka…
ale niestety nie zwraca pustych rekordów. znów wiąże się z operacjami na pustych zbiorach i wynika z prostej matematyki 'A ∩ B’. a jak się kończy mnożenie przez zero, to chyba nie trzeba mówić. jeśli nie wierzyła(e)ś, że powtórka z matematyki się przyda, to chyba powoli przestajesz mieć wątpliwości?
#4
pobawmy się zatem typem [flavor] joina:
$QUERY = "resourceContainers
| where type =~ 'microsoft.resources/subscriptions'
| project subscriptionId, subName=name
| join kind=leftouter resources on subscriptionId
| summarize nrOfResources=count() by subscriptionId,subName
| sort by nrOfResources asc"
Returns all the records from the left side and only matching records from the right side.
co powinno dobrze zadziałać, bo po lewej mamy WSZYSTKIE subskrypcje , nawet te które nie mają części wspólnej z zasobami…
..no i generalnie to działa. ale jest glitch. mianowicie puste subskrypcje pokazują '1′ zamiast '0′. a, że lubię drążyć… drążę dalej…
#5
oto finalne rozwiązanie:
$QUERY = "resourceContainers
| where type =~ 'microsoft.resources/subscriptions'
| project subscriptionId, subName=name
| join kind=leftouter
(resources
| summarize nrOfResources = count() by subscriptionId
) on subscriptionId
| extend nrOfResources = coalesce(nrOfResources, 0)
| sort by nrOfResources asc"
magiczną funkcją tutaj jest 'coalesce’,
która jest ekwiwalentem 'isNullOrEmpty’, oraz zamiana sekwencji wyliczania sumy – przed wykonaniem join a nie po nim. czy to rozwiązuje wszystkie problemy? no nie. nie ma np. ResourceGroup – jeśli będą Subscription bez zasobów, ale zawierające ResourceGroup – wynik będzie nadal '0′.
jak wszystko w tej dziedzinie – można wymyślić kilka innych wersji dających taki, lub nawet lepszy wynik, ale celem całego wpisu ma być pomoc tym, którzy z KQLem przygodę zaczynają, i podobnie jak ja – bazy danych/zbiory danych nie są ich chlebem powszednim. i jeśli jeszcze nie jesteś przekonana(y) – powtórka z działań na zbiorach będzie na prawdę pomocna, bo pozwala na zmianę sposobu myślenia z sekwencyjnego przetwarzania, na bardziej przestrzenne.
eN.


 w AD sprawa była prosta… no może nie tak bardzo prosta, bo historia atrybutów lastLogon i lastLogonTimeStamp też ma swoje drugie dno, ale od wielu lat wiadomo jak aktywność użytkownika zbadać… i pojawiła się Chmura i hybryda, która całość skomplikowała…
w AD sprawa była prosta… no może nie tak bardzo prosta, bo historia atrybutów lastLogon i lastLogonTimeStamp też ma swoje drugie dno, ale od wielu lat wiadomo jak aktywność użytkownika zbadać… i pojawiła się Chmura i hybryda, która całość skomplikowała…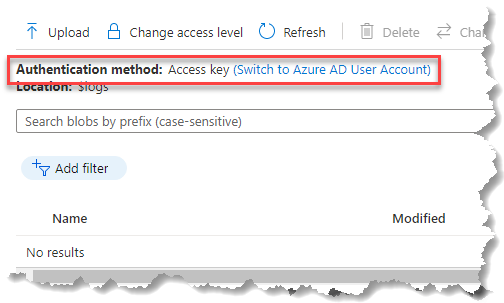 realnie interface po prostu korzysta z klucza – dokładnie tak, jak z commandline. jeśli przestawimy na 'AAD User Account’ wtedy od razu widać, że owner nie ma uprawnień:
realnie interface po prostu korzysta z klucza – dokładnie tak, jak z commandline. jeśli przestawimy na 'AAD User Account’ wtedy od razu widać, że owner nie ma uprawnień: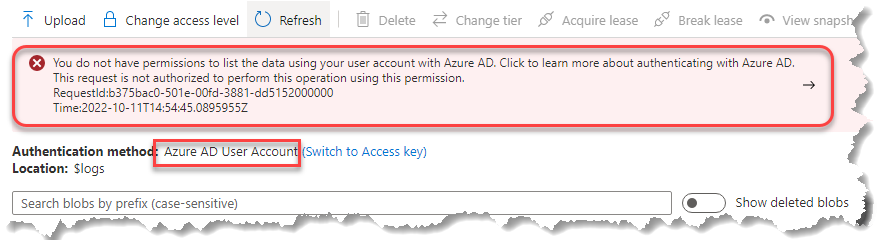

 albo ilość albo jakość. Microsoft niemal zawsze wybiera to pierwsze. a im większy jest Azure/o365 – tym gorzej ze stabilnością i jakością. błędów jak ten, który zaraz opiszę, jest masa, ale ten mnie po pierwsze rozśmieszył, po drugie to śmiech przez łzy – bo straciłem półtora tygodnia… może komuś oszczędzę tej przyjemności?
albo ilość albo jakość. Microsoft niemal zawsze wybiera to pierwsze. a im większy jest Azure/o365 – tym gorzej ze stabilnością i jakością. błędów jak ten, który zaraz opiszę, jest masa, ale ten mnie po pierwsze rozśmieszył, po drugie to śmiech przez łzy – bo straciłem półtora tygodnia… może komuś oszczędzę tej przyjemności?
 w jaki sposób ludzie zgłaszają problemy, chyba nie trzeba nikomu mówić. wydawałoby się, że zgłoszenia typu 'komputer mi niedziała’ powinny być domeną enduserowego ciemnogrodu… ale niestety rzeczywistość pokazuje, że w tej krainie mieszka również rzesza IT. klasycznym przykładem dnia codziennego są zgłoszenia, w których dostaję tylko adres IP. ba! zdarza się, że dev przysyła tylko publiczny URI aplikacji i trzeba szukać… /:
w jaki sposób ludzie zgłaszają problemy, chyba nie trzeba nikomu mówić. wydawałoby się, że zgłoszenia typu 'komputer mi niedziała’ powinny być domeną enduserowego ciemnogrodu… ale niestety rzeczywistość pokazuje, że w tej krainie mieszka również rzesza IT. klasycznym przykładem dnia codziennego są zgłoszenia, w których dostaję tylko adres IP. ba! zdarza się, że dev przysyła tylko publiczny URI aplikacji i trzeba szukać… /:


Classic Administrator – porządki i źle wyświetlane przypisanie
kolejny brzegowy przypadek. tym razem mógł mnie kosztować usunięcie istniejących subskrypcji – a więc 'niuans, który może zabić’.
scenariusz to clean up subskrypcji. jest ich kilkaset, więc trzeba podejść do tematu systemowo. najpierw zajmę się omówieniem scenariusza i moim podejściem do sprzątania, a jak kogoś interesuje sam bug w Azure – to będzie na końcu.
clean up process
w pierwszej kolejności trzeba wyizolować osierocone i puste subskrypcje. o tym jak znaleźć te puste szybko, czyli KQLem – za niedługo, wraz z małym qrsem KQL. dziś o tych 'osieroconych’.
duża część subskrypcji zakładana jest na chwilę, głównie przez developerów, którzy przychodzą i odchodzą…. a subskrypcje zostają. warto więc znaleźć te, których właściciele już nie istnieją w AAD.
zadanie wygląda więc tak – zrobić listing wszystkich subskrypcji wraz z osobami które są Ownerami w ARM IAM oraz Classic Administrators – czyli role Service Administrator oraz Co-Administrator. posłużą zarówno jako lista kontaktowa, oraz pozwolą na kolejne odpytania, żeby wyłuskać te konta, które już nie istnieją. subskrypcje bez właścicieli to najlepsze kandydatki do podróży do śmietnika. posłuży do tego taki prosty skrypcik, napisany na kolanie:
$csvOwnerFile = "c:\temp\subsAndOwners.csv" Get-AzSubscription | ? {$_.state -ne 'disabled'} | %{ $subname= $_.Name $subID = $_.SubscriptionId Set-AzContext -Subscription $_|Out-Null write-host "processing $subname..." Get-AzRoleAssignment -IncludeClassicAdministrators | ? { ($_.RoleDefinitionName -eq 'owner' -or $_.RoleDefinitionName -match 'administrator') -and ([string]::IsNullOrEmpty($_.RoleAssignmentId) -or $_.RoleAssignmentId -match 'subscriptions') } | select @{L='SubscriptionName';E={$subname}},@{L='subscriptionID';E={$subID}},RoleDefinitionName,DisplayName,SignInName,roleassignmentid } | export-csv -nti -Encoding utf8 -Path $csvOwnerFile &(convert-CSV2XLS $csvOwnerFile)$users = load-CSV c:\temp\subsAndOwners.csv connect-azuread $users.SignInName | select -unique | %{ $u=Get-AzureADUser -SearchString $_; if([string]::IsNullOrEmpty($u)) {write-host "$_" -ForegroundColor Red} }load-CSV to kolejna funkcja z eNlib – jedna z najczęściej przeze mnie używanych. ładuje CSV z automatyczną detekcją znaq oddzielającego, co jest mega istotne jak się pracuje w różnych regionalsach. ma też kilka innych bajerów… ale nie o tym tu. dalej już z górki – wyłusqję SignInNames unikalne i odpytuję AAD o użytkownika. ponieważ brak użytkownika nie jest błędem, a nullem, więc nie można użyć try/catch a trzeba wykorzystać IFa.
i wydawałoby się że mam już to, co potrzeba – wrzucam wynik do excela, robię XLOOKUP i pięknie widać które subskrypcje należą do kont, których już wśród nas nie ma… zabrzmiało złowieszczo khekhe…
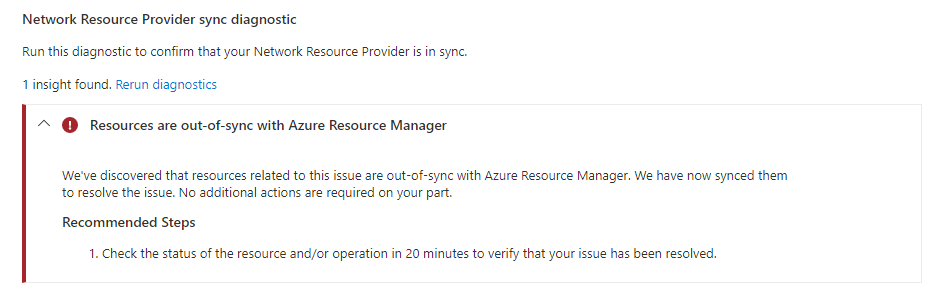
Błąd w Azure
…chyba, żeby nie. całe szczęście natchnęło mnie, żeby jednak kilka posprawdzać ręcznie. i nagle okazało się, że konta których nie ma… czasem jednak są. a wszystko rozbija się o 'Classic Administrators’, który musi wewnętrznie źle komunikować się z ARMem. wiele staje się jaśniejsze, jeśli przyjrzeć się jak takie obiekty są listowane przy 'get-AzRoleAssigment -includeClassic’:
na pierwszy rzut okiem może wydawać się, że jest ok… ale gdzie jest 'ObjectId’? to jednak tylko pierwsza część problemu. porządki mają to do siebie, że robi się je rzadko. a to oznacza bagaż historii. a w tym bagażu np. projekt standaryzacji nazw użytkowników i zmiana UPNów z gsurname@domain.name na givenname.surname@domain.name. okazuje się, że ten staruszek nie ma mechanizmu odświeżania i pomimo zmiany UPN, czyli de facto SignInName, tutaj pokazuje starą nazwę. a więc przy odpytaniu AAD – nie znajduje usera, pomimo, że ten istnieje.
co ciekawe, jeśli wejdzie się do uprawnień IAM w portalu Azure, każdy user jest aktywnym linkiem, pozwalającym na kliknięcie i przeniesienie do AAD, na szczegóły konta. tak z ciekawości spróbujcie to zrobić dla Classic Administrators…
całe szczęście projekt był zrobiony z głową i stare UPNy zostały jako aliasy mailowe, a więc doprecyzowałem zapytanie:
$users.SignInName | select -unique |%{ $u=Get-AzureADUser -Filter "UserPrincipalName eq '$_' or proxyAddresses/any(p:startswith(p,'smtp:$_'))"; if([string]::IsNullOrEmpty($u)) {write-host "$_" -ForegroundColor Red} }ale co mnie to czasu i nerwów kosztowało…
eN.