commandlety dla SCCM
SCCM Team wydał commandlety PowerShell dla Configuration Managera.
eN.


 cluster Hyper-v na w2k12R2. czy zmiana nazwy węzła jest wspierana? bez problemu – evict, zmiana nazwy, restart, dodanie. system bez problemu sobie z tym radzi.
cluster Hyper-v na w2k12R2. czy zmiana nazwy węzła jest wspierana? bez problemu – evict, zmiana nazwy, restart, dodanie. system bez problemu sobie z tym radzi.
… gorzej z System Center. żaden produkt tego nie przeżył.
VMM – nie był w stanie ani wyrzucić węzła ani dodać [bo już istnieje z takim GUIDem] ani odświeżyć [bo nie istnieje]. trzeba było usunąć klaster i dodać jeszcze raz. cała konfiguracja związana z maszynami [np. przypisanie do chmury] idzie z dymem. szczęśliwie w tym środowisq nie była to konfiguracja zbyt wyszukana.
DPM – gorzej. wszystkie backupy potraciły dowiązania. być może dałoby się coś tam porzeźbić… ale skończyło się na wykonaniu nowych backupów.
CM – zgubił informacje o hostach – zostały stare nazwy, których nie sposób powiązać z realnymi hostami. trzeba było ręcznie usunąć i dodać jeszcze raz…
w skrócie – zmiana nazwy hosta w clustrze *nie jest wspierana* powyżej samego OSa.
eN.
nie zrobiłem screenshota /: więc tak pół-informacyjnie: po instalacji UR5 do SCVMM zaczął sypać błędami podczas zakładania maszyny wirtualnej. coś w stylu:
„method get_protectionProvider in type hardwareConfigSettingsAdapter from assembly microsoft.systemcenter.virtualmachinemanager does not have an implementation”
kombinowaliśmy z poprawkami do .NET framework, których ostatnio trochę się pojawiło, ale dopiero cofnięcie UR5 pomogło. sądząc po braq wyników w googlu chyba mieliśmy odosobniony przypadek…
eN.
 „tyle magii w całym mieście,
„tyle magii w całym mieście,
nie widziałeś tyle jeszcze,
popatrz.. o popatrz…”
dzisiejszy dzień mianuję swoim 'dniem archeologa’. podstawowe założenia – cuda nie istnieją. ale kategoria i tak do w-files. a wszystko zaczęło się od zupełnie zwykłego taska administracyjnego opisywanego w poprzednim wpisie: trzeba usunąć CSV i stworzyć nowy. czyli musi być jakiś pośredni – temp, i maszynki trzeba przenieść najpierw na tempa, dokonać odpowiednich modyfikacji na macierzy, stworzyć nowe CSV i na nie poprzenosić już docelowo maszyny. no i się zaczęło…
podczas przenoszenia maszyn, wszystko idzie sprawnie, aż na koniec informacja, że migracja nie powiodła się. efekty różne łącznie z takim, że maszyna po prostu znika! (SIC!) ale żeby jeszcze zupełnie znikęła, a to nie – niby jest a jej nie ma. niby jej nie ma, a jest… no po prostu burdel na kółkach. ale udało się dużą część wyjaśnić…
finalnie okazało się, że są dwa powody nieudanych migracji: jeden to snapshoty DPM a drugi to jakiś wewnętrzny błąd SCVMM, którego póki co nie umiem wyjaśnić.
przypadek ciekawszy, ponieważ po wykonaniu migracji maszyna jest, ale jej nie ma. błąd migracji:
Error (2901)
The operation did not complete successfully because of a parameter or call sequence that is not valid.
The parameter is incorrect (0x80070057)Recommended Action
Ensure that the parameters are valid, and then try the operation again.
maszyna pozostaje w VMM z informacją 'incomplete VM Configuration’. jest również widoczna w klastrze, ale zasób konfiguracji jest niedostępny. natomiast, żeby było ciekawie, zostaje wyrejestrowana z samego hosta Hv. po analizie logów na hoście Hv, na którym maszyna była zarejestrowana pojawiają się na koniec migracji trzy wpisy:
owy plik, który cannot be found to snapshot zrobiony przez DPM. okazuje się, że w wyniq utraty komunikacji w trakcie robienia backupu, DPM zostawia informację o snapshocie. specjalnie napisałem 'informację’ ponieważ okazuje się, że jest xml z informacją, widać go w interfejsie tudzież używając get-vmsnapshot, ale sam katalog, gdzie powinny znajdować się pliki snapshota (vsv i bin), jest pusty. sam proces 'storage migration’ działa jako: export VM -> delete VM-> import VM, wywala się na ostatnim kroq. maszyna zostaje usunięta z Hv, a durny VMM nie zapewnia atomowości. nie dość, że migracja się nie udaje, zostają pełne zapisy w clustrze i VMM, sama maszyna znika.
po fakcie jest tylko jeden sposób:
a żeby zapobiec, najlepiej zrobić hurtowe zapytanie o snapshoty typu recovery i je pousuwać. łatwo odróżnić te, które są 'w trakcie’ do tych, które wiszą, ponieważ w nazwie mają daty:
VMName Name SnapshotType CreationTime ------ ---- ------------ ----------- VMo1 VMo1 - Backup - (2014-11-19 - 23:19:08)Recovery 2014-11-... VMo2 VMo2 - Backup - (2014-11-19 - 23:44:42)Recovery 2014-11-...
widać, że to są jakieś snapy z przed wielu dni, więc na pewno do wywalenia. po upewnieniu się, że wszystkie są stare i żaden backup teraz się nie wykonuje:
Get-ClusterNode -Cluster <CLUSTER>|%{$h=$_.name;get-vm -VMHost $h|%{Get-VMSnapshot -ComputerName $h -VMName $_.name|? snapshotType -eq 'recovery'|Remove-VMSnapshot}}
następnie warto odświeżyć VMM, ponieważ ma stare informacje. można np. hurtem wszystkie maszyny: get-scVirtualMachine|read-scVirtualMachine|out-null
drugi przypadek jest dziwny i wygląda na wewnętrzny błąd VMM. migracja wywala się w ostatnim etapie z błędem o niedostępności zasobu. po weryfikacji okazuje się, że maszyna jest jednak zmigrowana i dyski wskazują na nowy CSV. jeśli jednak spojrzy się do konsoli klastra okazuje się, że maszyna ma w zależnościach wpisy dotyczące i starego i nowego CSV. to dokładnie efekt opisywany ostatnio.
analiza polega na spostrzegawczości. błąd migracji jest następujący:
Error (12711)
VMM cannot complete the WMI operation on the server (<HOSTNAME.FQDN>) because of an error: [MSCluster_Resource.Name="SCVMM VMNAME Configuration"] Element not found.Element not found (0x490)
Recommended Action
Resolve the issue and then try the operation again.
natomiast po przyjrzeniu się wynikom czy to z PS czy w interfejsie widać, że maszyna nazywa się po prostu 'VMNAME’ a nie 'SCVMM VMNAME’ /:
VMM jest głupi.
post factum można to zrobić tak, jak we wspomnianym wpisie – czyli przez WMI usunąć z privateparts zależność do dysq. można to też zrobić prościej – i metoda powinna dać efekt post factum et pro eo – odświeżyć konfigurację maszyny na klastrze:
Update-ClusterVirtualMachineConfiguration -Cluster <CLUSTER> -name 'Virtual Machine Configuration <VMNAME>'
a bo inne ciekawe przypadłości podczas całej operacji wyszły, mniej-lub-bardziej wyjaśnialne. ot np. taki niuans:
jedna maszyna ma w VMM status 'incomplete VM configuration’ a VMM pokazuje, że maszyna jest na hoście HOSTo3. w klastrze ta sama maszyna działa i ma się dobrze, i działa na hoście HOSTo5. póki co nijak nie udało mi się odświeżyć tej maszyny. prawdopodobnie trzeba to będzie zrobić via SQL. ale jeszcze fajniejsza rzecz:
PS C:\scriptz> get-vm -VMHost HOSTo3|select name Name ---- VMo1 VMo2 VMo3
załóżmy, że ta VMo2 to ta, której nie ma. to samo polecenie dla hosta, na którym ta maszyna działa, nie pokazuje jej. ale przecież Hv manager jej nie pokazuje, i jej tam nie ma! o co c’mon? otwieram drugą konsolę, kopiuję polecenie i…
PS C:\Users\nz.adm> get-vm -VMHost HOSTo3|select name
Get-VM : A parameter cannot be found that matches parameter name 'VMHost'.
At line:1 char:8
+ get-vm -VMHost HOSTo3|select name
+ ~~~~~~~
+ CategoryInfo : InvalidArgument: (:) [Get-VM], ParameterBindingException
+ FullyQualifiedErrorId : NamedParameterNotFound,Microsoft.HyperV.PowerShell.Commands.GetVMCommand
eeeee.. ale że o co c’mon? i znów na spostrzegawczość: przecież get-VM nie ma parametru 'VMHost’ tylko 'ComputerName’ – co zresztą podpowiada tab. zatem muszą to być dwa różne polecenia… oto odpowiedź:
konsola A
PS C:\scriptz> Get-Command get-vm
CommandType Name ModuleName
----------- ---- ----------
Alias Get-VM
PS C:\scriptz> man get-vm
NAME
Get-SCVirtualMachine
SYNTAX
Get-SCVirtualMachine [[-Name] <string>] [-VMMServer <ServerConnection>] [-All] [
fOfUserRole <UserRole>] [<CommonParameters>]
konsola B
PS C:\scriptz> Get-Command get-vm
CommandType Name ModuleName
----------- ---- ----------
Cmdlet Get-VM Hyper-V
PS C:\scriptz> man get-vm
NAME
Get-VM
SYNTAX
Get-VM [[-Name] <string[]>] [-ComputerName <string[]>] [<CommonParameters>]
VMM jest nie tylko głupi, ale również wredny.
eN.
 niedawno na w-files pojawił się pierwszy wpis Ozz’a. dotyczył DPM. dziś premierę ma Tommy – temat również DPMowy (: zapraszam do lektury i komentarzy. dodam tylko, że opisywane metody nie są oficjalne i nie autor nie ręczy za ew. problemy.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.
niedawno na w-files pojawił się pierwszy wpis Ozz’a. dotyczył DPM. dziś premierę ma Tommy – temat również DPMowy (: zapraszam do lektury i komentarzy. dodam tylko, że opisywane metody nie są oficjalne i nie autor nie ręczy za ew. problemy.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.
Data Protection Manager zarządza dyskami w bardzo specyficzny sposób – kto nie zna DPM i otworzy diskmanagera, spadnie z krzesła. Dla każdego backupu tworzone są dwie partycje(dla repliki i recovery pointa), które potem są albo rozszerzane, albo spanowane. Widok przypomina trochę bardzo długi kod ISDN. Taka obsługa partycji oraz metoda oparta na bitmapie zmian, niesie ze sobą nieprzyjemne konsekwencje – w niektórych scenariuszach DPM zaczyna bardzo niewydajnie zarządzać przestrzenią. Są dwa podstawowe scenariusze, w których przestrzeń jest źle wykorzystywana, i różne metody naprawy.
Pierwszy scenariusz związany jest z przenoszeniem dużych plików baz danych – np. przeniesienie całego mailbox store na inny dysk. DPM może po takiej operacji wykonać kopię różnicową o wielkości dwukrotnie większej niż oryginał i dodatkowo zaalokować przestrzeń na kolejny. W przypadku o którym piszę, dla bazy 16oGB DPM zarezerwował 25oGB przestrzeni na pojedynczy recovery point. w tym scenariuszu jest tylko jedno skuteczne remedium– należy usunąć backup i utworzyć go od nowa. Należy oczywiście jakoś poradzić sobie z archiwami – w końcu nie zawsze można sobie pozwolić na takie ‘ot, wywalenie backupów’.
Jednak nawet podczas regularnej pracy operacyjnej DPM ma problemy z wydajnym zarządzaniem przestrzenią i wiele miejsca się marnuje – alokuje ilość przestrzeni daleko przekraczającą potrzeby. Można to zweryfikować otwierając zdefiniowany raport – Disk Utilization. Jesk kilka możliwości wygenerowania takiego raportu: per komputer, protection grupa oraz klient. Najbardziej obrazującym (i jednocześnie na pierwszy rzut oka najbardziej nieczytelnym) raportem jest per komputer:

„Total Disk Capacity” to wielkość jaką mamy do dyspozycji na backupy. „Disk Allocated” oznacza jaka przestrzeń została zaalokowana na backupy. „Disk Used” określa ile nasze backupy naprawdę zajmują. Jak widać na załączonym obrazku, sumaryczna zaalokowana przestrzeń jest o kilka TB większa, niż ta potrzebna na same backupy (prawie 21TB zaalokowanej vs 13TB używanej).
Podstawowe pytanie, jakie przychodzi do głowy to jak tą przestrzeń uwolnić? Są dwie odpowiedzi.
Pierwsza to wykonać shrink w samym DPMie. Można to zrobić klikając na nasz backupowany serwer i z listy wybrać „Modify disk allocation”. Otworzy się okno, w którym możemy zwiększyć wielkości repliki i recovery pointa oraz zrobić shrink, ale TYLKO RECOVERY POINTA.
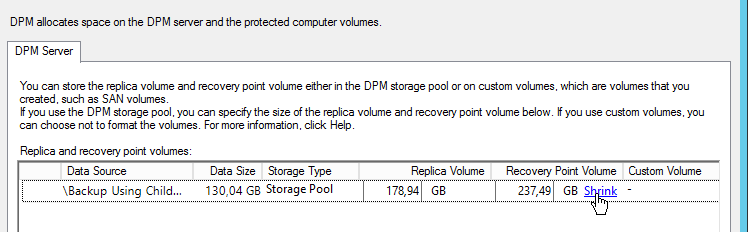
Klikając na link „Shrink” uruchamia się zadanie wykonujące zmiejszenie wielkości wolumenu. Czasami da się zmniejszyć jego wielkość, a czasami nie. DPM zmniejsza wielkość automatycznie pozostawiając sobie „trochę” wolnej przestrzeni. W opisywanym przypadku udało się zmniejszyć wolumen o 30 GB.
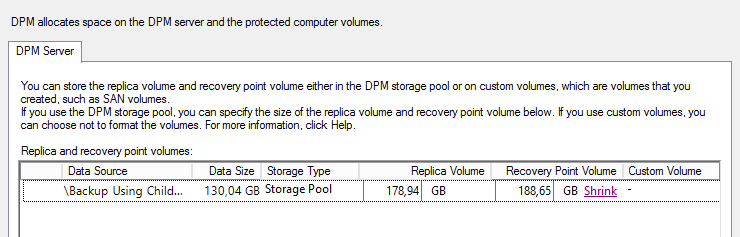
Super, nie? Sprawdźmy jeszcze czy da się ponownie zmniejszyć tą przestrzeń.
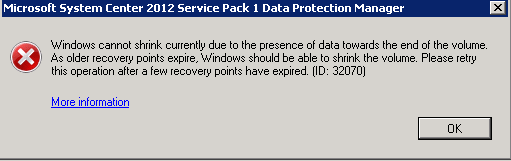
Cóż, pozostało nam do przeklikania jeszcze 100 recovery pointów J (lub tyle ile mamy backupowanych serwerów). Biorac pod uwagę, że ta operacja zajmuje od kilku do kilkunastu minut mamy z głowy cały dzień o ile nie zna się powershella ale to już inna historia.
Ok to tę część mamy z głowy. Nie? A już wiem. Pewnie zastanawiacie się co z wielkością repliki? A co ma z nią być – z poziomu DPM nie da się zmniejszyć jej wielkości. I tu na tym jednym backupie tracimy 100 GB.
Co zatem zrobić z takimi 20 serwerami, które mają zaalokowane po +100GB per replika? Tu przychodzi nam z pomocą narzędzie zwane „Disk Manager” J. Otwórzmy go teraz i sprawdźmy ile mamy jeszcze wolnej przestrzeni na naszym wolumenie.
Zacznijmy jednak od „Recovery Point”. We wspomnianym narzędziu zrobię „shrinka”. Ze 188GB przestrzeni do zwolnienia jest 77 GB.
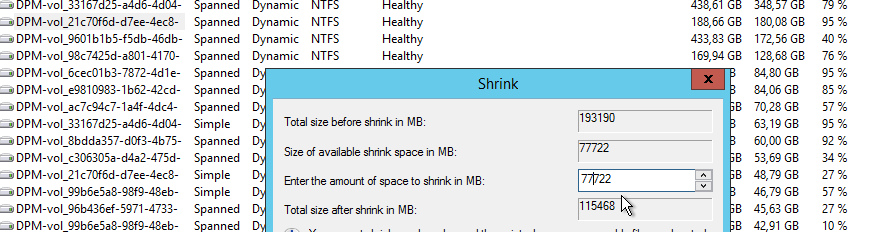
Odzyskajmy jeszcze 30 GB.
Ok, to teraz czas na repliki. Nie da się zmniejszyć wilekości wolumenu repliki z poziomu DPM. Jedynym sposobem jest wykonanie tej operacji za pomocą „Disk Managera”. Prawy przycisk myszki na wolumenie i klikamy na shrink. Pamiętajmy o tym, aby nie zmniejszać przestrzeni o więcej, niż połowę za jednym razem. Co prawda nie jest to zabronione, ale z doświadczenia – gdy zmniejszamy za dużo, operacja się często nie udaje.
Jak skończymy, robimy „rescan” dysków w konsoli DPM (aby od razu wolne miejsce zostało dodane do niezaalokowanej przestrzeni).
Jest jeszcze kilka rzeczy, które mam nadzieję zostaną ulepszone takie jak shrinkowanie wielkosci repliki czy optymalizacja backupu na taśmy. Na chwilę obecną pozostaje nam czekać i mieć nadzieję, że te zmiany nastąpią.
Tommy.
dziś na szybko, bez tłumaczenia. skrypt get-DPMGroupToDataAssociation.ps1:
Get-DPMProtectionGroup |%{$pg=$_; $ds=Get-DPMDatasource $_ ; $ds|%{`
Add-Member -MemberType noteproperty -InputObject $_ -Name PGname -Value $pg.name -force}; $ds}
i potem można np:
get-DPMGroupToDataAssociation | select PGname,computer
eN.
Sytuacja prosta, System Center Data Protection Manager 2012 R2 robi backup dysków, udziałów, ale nie potrafi poradzić sobie ze zrobieniem Bare Metal Recovery oraz System State.
![]()
Server Backup na maszynie, którą chcemy backupować wypisuje „VSS – Failed” i dalej: „there is not enough disk space to create the volume shadow copy on the storage location”. Jak to nie ma miejsca, jak na macierzy mam go od groma.
Na koniec jeszcze Event Viewer po stronie backupowanego klienta:
“The backup operation that started at '2014-08-25T13:22:49.633000000Z’ has failed because the Volume Shadow Copy Service operation to create a shadow copy of the volumes being backed up failed with following error code '0x80780119′. Please review the event details for a solution, and then rerun the backup operation once the issue is resolved.”
Prawdopodobnie problem leży w partycji Recovery Point o pojemności 300MB. VSS potrzebuje przynajmniej 50MB wolnego miejsca. Jeżeli go nie ma Backup, nawet nie ruszy.
Wolne miejsce w prosty sposób sprawdzimy używając polecenia PowerShell’owego po stronie maszyny, którą chcemy backup’ować.
Get-Volume
W wyniku, którego widzimy, że nasza partycja Recovery ma 300 MB, z czego tylko 29,99MB wolnego.

Upssss, niecałe 30MB to trochę za mało, do 50 kawałek brakuje…
Ponieważ problem leży w przestrzeni dyskowej po stronie klienta, rozwiązaniem będzie zwolnienie go, poprzez przeniesienie „shadowcopy storage” dla tego wolumenu („recovery partition volume”) na inny dysk.
Przy wykorzystaniu starego vssadmin pozostając w PS:
vssadmin list volumes
Zaznaczamy interesującą nas partycję Recovery (nie ma dopisanej żadnej litery)
Przyjmując, że korzystamy z PowerShell’a w wersji 3 zadziała poniższe polecenie(dzięki wykorzystaniu –% PS nie będzie analizował pozostałej linii kodu) przy wersjach wcześniejszych możemy, żeby było najprościej użyć cmd.exe /c lub powalczyć ze znakami specjalnymi PowerShell (więcej info tutaj)
vssadmin --% add shadowstorage /for=\\?\Volume{7497305d-c678-4907-8274-e2f21de66bae}\ /on=c: /maxsize=500MB
Wracamy na nasz serwer do konsoli System Center Data Protection Manager, prawym na Protection Group z naszym serwerem i wykonujemy Perform consistency check…
Wszystko powinno wykonać się poprawnie.
Ozz.
przy próbie podniesienia wersji DPM 2o1o do 2o12 SP1 dostaję informację, iż nie jest wspierana i należy postawić DPM2o12 SP1 obok. taką migrację da się jednak zrobić, z krokiem pośrednim, którym jest DPM 2o12 bez SP1:
DPM2o1o -> DPM2o12 -> DPM2o12 SP1
czemu tak? ze względu na ograniczenia w ilości sprzętu, żeby nie przenosić potem konfiguracji i zachować całą historię backupów.

in-place upgrade nie jest specjalnie skomplikowany ale interfejs jest na tyle niejasny, że można się obawiać, co się tak na prawdę robi i jak to się zakończy. że się w ogóle da i żeby się nie bać przeczytałem sobie tutaj, jednak to koniec wartości tego wpisu. zabrakło kilq ważnych informacji.
sporo drobiazgów, a stresik jest.
eN.
Obronić się przed MiTM
Minęło wiele lat od kiedy napisałem tu ostatni post a do tego temat na (re)debiut już nie jest gorący. Chociaż z drugiej strony nie zdążył jeszcze wystygnąć i w każdej chwili może ponownie wybuchnąć. Ale do rzeczy. Dziesięć miesięcy temu okazało się, że przez pół roku Lenovo raczyło swoich użytkowników certyfikatami umożliwiającymi ataki MiTM (https://www.us-cert.gov/ncas/alerts/TA15-051A). Wiadomo, generalne oburzenie, Chińczycy nas śledzą, na pewno to sprawa służb, teorie spiskowe i w ogóle koniec świata. Szczerze mówiąc temat spłynął po mnie jak po kaczce, sprawdziłem swój tablet (kupiony w przypływie weny wracając z baru po spotkaniu świąteczno noworoczny) i zapomniałem o temacie. Potem gdzieś pojawił się problem z Dell System Detect i zdalnym wywołaniem kodu, który został załatany przed opublikowaniem dziury (http://tomforb.es/dell-system-detect-rce-vulnerability). To ruszyło mnie trochę bardziej, sprawdzanie kto ma zainstalowane oprogramowanie i usunięcie starych wersji okazało się nie być trzema kliknięciami ale koniec końców temat załatwiony i systemy załatane w kilka godzin.
Niby dwie z pozoru niepowiązane rzeczy a jednak ostatnio okazało się, że niektórzy wolą się uczyć na własnych błędach zamiast na cudzych i Dell obdarzył nas kolejną serią serią wpadek (http://joenord.blogspot.in/2015/11/new-dell-computer-comes-with-edellroot.html,http://www.kb.cert.org/vuls/id/925497) instalując razem ze swoim oprogramowaniem certyfikaty w Trusted Root razem z ich kluczami prywatnymi. Do tej pory jest jeszcze prawie ok. Oprogramowanie potrzebuje coś samo podpisać żeby system się nie burzył przy instalacji, certyfikat jest oznaczony jako nieeskportowalny. Nie jest najgorzej, w końcu to narzędzie systemowe a nie aplikacja pokazujące reklamy jak w przypadku Lenovo i jesteśmy zadowoleni dopóki nie zauważymy, że nasz kolega ma ten sam certyfikat a ktoś nam powie, że klucz prywatny można wyeksportować na przykład za pomocą mimikatz.
W głowie zaczynają układać się klocki pokazujące bardzo prosty scenariusz ataku:
Problem pojawia się kiedy zdamy sobie sprawę, że nie tylko my możemy tak zrobić a nasi użytkownicy na pewno nie sprawdzają za każdym razem kto wystawił certyfikat stronie i możemy się założyć, że kwestią czasu jest kiedy wypłyną dane z naszej firmy albo ktoś dostanie karnego na Facebook’u. A co jeśli nie tylko Dell i Lenovo mają problem z certyfikatami? Będziemy czekać na białe kapelusze aż opublikują artykuły i łatać za każdym razem licząc na to, że czarne kapelusze nie wkroczyły jeszcze do akcji? A może pójdziemy o krok dalej i będziemy bardziej proaktywni sprawdzając czy mamy jakiekolwiek podejrzane certyfikaty na naszych komputerach?
Teoria mówi, że żaden certyfikat znajdujący się w Trusted Root Certification Authorities nie powinien mieć klucza prywatnego. Gdzieś daleko od nas jest CA a my jemu ufamy ponieważ znamy klucz publiczny CA pasujący do klucza prywatnego używanego do podpisywania certyfikatów. Tyle teorii, praktyka okazuje się być trochę bardziej brutalna ale o tym później.
Kiedy mamy problem z pomocą przychodzi korporacyjna nowomowa i nagle problem staje się on wyzwaniem, a kto nie lubi wyzwań? Do tego jeszcze można zaprzęgnąć lubianego PowerShell i System Center lubiane … inaczej ;)
Zaczynamy od kawałka banalnego kodu:
foreach($BaseStore in Get-ChildItem cert:\) { Get-ChildItem $BaseStore.PSPath -Exclude "My","Remote Desktop","SMS" |ForEach-Object{ [array]$comptmp = Get-ChildItem $_.PSPath |Where-Object { $_.HasPrivateKey ` -and $_.Subject -notmatch 'DO_NOT_TRUST_FiddlerRoot' ` -and $_.Subject -notmatch $env:COMPUTERNAME } [array]$Compromised += $comptmp } } if($Compromised.Count -eq 0){ return "Compliant" } else { $output = ($Compromised | Out-String) return $output }Który przeleci nam po wszystkich dostępnych certificates stores wyłączając z tego:
w tym kroku można się pokusić jeszcze o wyłączenie innych rzeczy (np. certyfikatów klienta SCOM) albo zamianę
na
żeby zaglądać tylko do Trusted Roots. Na razie trzymajmy się pierwszej wersji żeby zobaczyć co się w ogóle dzieje.
Jak już wiemy jakie mamy Certificates Stores to warto do nich zajrzeć i zobaczyć jakie mamy certyfikaty z kluczami prywatnymi
[array]$comptmp = Get-ChildItem $_.PSPath |Where-Object { $_.HasPrivateKey ` -and $_.Subject -notmatch 'DO_NOT_TRUST_FiddlerRoot' ` -and $_.Subject -notmatch $env:COMPUTERNAME }żeby uniknąć szumu wywalamy:
Reszta to proste działania mające na celu sprawdzenia czy mamy jakiekolwiek podejrzane certyfikaty i podanie ich listę lub potwierdzenie, że komputer jest ok.
Kiedy mamy już PowerShell to warto byłoby uruchomić go na wszystkich komputerach i sprawdzić kto ma coś podejrzanego na swojej maszynie. Fajnie byłoby też aby sprawdzanie odbywało się cyklicznie i informowało nas kiedy jest coś nie tak. Tutaj przydaje się SCCM i Compliance Settings.
Tworzymy Configuration Item uruchamiające skrypt i sprawdzające co jest na wyjściu
Configuration item
Compliance Rules
Compliance Rule
Potem robimy Configuration Baseline, dodajemy do niego nasz Configuration Item i robimy Deploy na kolekcje użytkowników oraz na kolekcje komputerów (odpowiednio All Users i All Systems). Ostatnie może się wydać trochę dziwne ale jest potrzebne żeby sprawdzić zarówno co mają użytkownicy jak i konto local system. Configuration baseline uruchomiony w kontekście systemu (Deploy na kolekcję komputerów) nie może zajrzeć do certyfikatów użytkowników bo te są trzymane w profilach*, a użytkownicy nie mogą zobaczyć jakie certyfikaty ma konto local system, za to zarówno użytkownik jak i local system mogą sprawdzić zawartość Certificate Store: Local Machine.
*-to nie jest do końca prawda bo można podmontować Hive i dekodować certyfikaty ale są na to prostsze sposoby
Jakby ktoś się pokusił dodatkowo o Remediation script żeby usuwać podejrzane certyfikaty to warto pamiętać, że Local System będzie mógł usuwać certyfikaty zarówno swoje jak o Local Machine a użytkownik będzie mógł usuwać wyłącznie swoje.
Na koniec pozostaje skonfigurowanie alertów, wysyłanie ich do SCOM i workflow do obsługi zdarzeń ale to już temat na osobny wpis.