 niedawno na w-files pojawił się pierwszy wpis Ozz’a. dotyczył DPM. dziś premierę ma Tommy – temat również DPMowy (: zapraszam do lektury i komentarzy. dodam tylko, że opisywane metody nie są oficjalne i nie autor nie ręczy za ew. problemy.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.
niedawno na w-files pojawił się pierwszy wpis Ozz’a. dotyczył DPM. dziś premierę ma Tommy – temat również DPMowy (: zapraszam do lektury i komentarzy. dodam tylko, że opisywane metody nie są oficjalne i nie autor nie ręczy za ew. problemy.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.oOo.
Data Protection Manager zarządza dyskami w bardzo specyficzny sposób – kto nie zna DPM i otworzy diskmanagera, spadnie z krzesła. Dla każdego backupu tworzone są dwie partycje(dla repliki i recovery pointa), które potem są albo rozszerzane, albo spanowane. Widok przypomina trochę bardzo długi kod ISDN. Taka obsługa partycji oraz metoda oparta na bitmapie zmian, niesie ze sobą nieprzyjemne konsekwencje – w niektórych scenariuszach DPM zaczyna bardzo niewydajnie zarządzać przestrzenią. Są dwa podstawowe scenariusze, w których przestrzeń jest źle wykorzystywana, i różne metody naprawy.
Pierwszy scenariusz związany jest z przenoszeniem dużych plików baz danych – np. przeniesienie całego mailbox store na inny dysk. DPM może po takiej operacji wykonać kopię różnicową o wielkości dwukrotnie większej niż oryginał i dodatkowo zaalokować przestrzeń na kolejny. W przypadku o którym piszę, dla bazy 16oGB DPM zarezerwował 25oGB przestrzeni na pojedynczy recovery point. w tym scenariuszu jest tylko jedno skuteczne remedium– należy usunąć backup i utworzyć go od nowa. Należy oczywiście jakoś poradzić sobie z archiwami – w końcu nie zawsze można sobie pozwolić na takie ‘ot, wywalenie backupów’.
Jednak nawet podczas regularnej pracy operacyjnej DPM ma problemy z wydajnym zarządzaniem przestrzenią i wiele miejsca się marnuje – alokuje ilość przestrzeni daleko przekraczającą potrzeby. Można to zweryfikować otwierając zdefiniowany raport – Disk Utilization. Jesk kilka możliwości wygenerowania takiego raportu: per komputer, protection grupa oraz klient. Najbardziej obrazującym (i jednocześnie na pierwszy rzut oka najbardziej nieczytelnym) raportem jest per komputer:

„Total Disk Capacity” to wielkość jaką mamy do dyspozycji na backupy. „Disk Allocated” oznacza jaka przestrzeń została zaalokowana na backupy. „Disk Used” określa ile nasze backupy naprawdę zajmują. Jak widać na załączonym obrazku, sumaryczna zaalokowana przestrzeń jest o kilka TB większa, niż ta potrzebna na same backupy (prawie 21TB zaalokowanej vs 13TB używanej).
Podstawowe pytanie, jakie przychodzi do głowy to jak tą przestrzeń uwolnić? Są dwie odpowiedzi.
Pierwsza to wykonać shrink w samym DPMie. Można to zrobić klikając na nasz backupowany serwer i z listy wybrać „Modify disk allocation”. Otworzy się okno, w którym możemy zwiększyć wielkości repliki i recovery pointa oraz zrobić shrink, ale TYLKO RECOVERY POINTA.
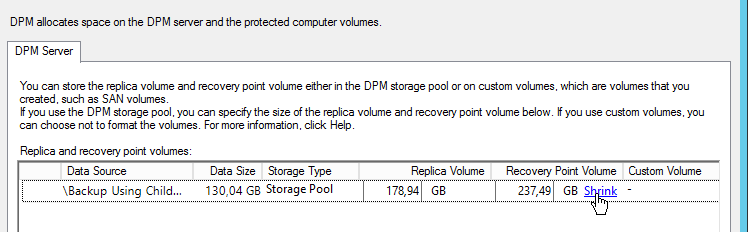
Klikając na link „Shrink” uruchamia się zadanie wykonujące zmiejszenie wielkości wolumenu. Czasami da się zmniejszyć jego wielkość, a czasami nie. DPM zmniejsza wielkość automatycznie pozostawiając sobie „trochę” wolnej przestrzeni. W opisywanym przypadku udało się zmniejszyć wolumen o 30 GB.
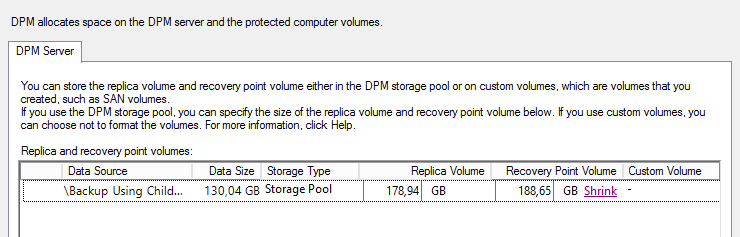
Super, nie? Sprawdźmy jeszcze czy da się ponownie zmniejszyć tą przestrzeń.
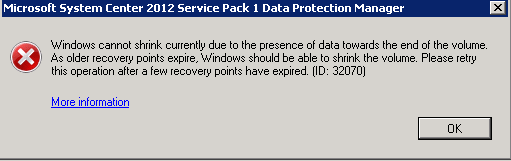
Cóż, pozostało nam do przeklikania jeszcze 100 recovery pointów J (lub tyle ile mamy backupowanych serwerów). Biorac pod uwagę, że ta operacja zajmuje od kilku do kilkunastu minut mamy z głowy cały dzień o ile nie zna się powershella ale to już inna historia.
Ok to tę część mamy z głowy. Nie? A już wiem. Pewnie zastanawiacie się co z wielkością repliki? A co ma z nią być – z poziomu DPM nie da się zmniejszyć jej wielkości. I tu na tym jednym backupie tracimy 100 GB.
Co zatem zrobić z takimi 20 serwerami, które mają zaalokowane po +100GB per replika? Tu przychodzi nam z pomocą narzędzie zwane „Disk Manager” J. Otwórzmy go teraz i sprawdźmy ile mamy jeszcze wolnej przestrzeni na naszym wolumenie.
Zacznijmy jednak od „Recovery Point”. We wspomnianym narzędziu zrobię „shrinka”. Ze 188GB przestrzeni do zwolnienia jest 77 GB.
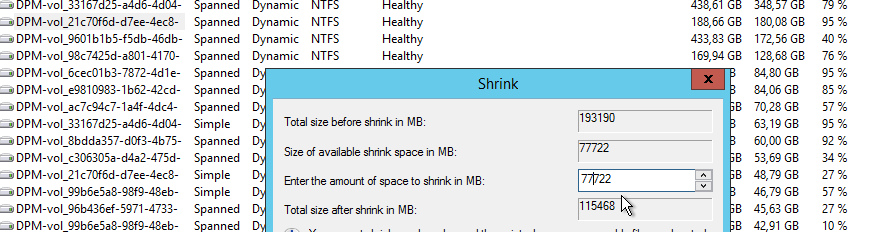
Odzyskajmy jeszcze 30 GB.
Ok, to teraz czas na repliki. Nie da się zmniejszyć wilekości wolumenu repliki z poziomu DPM. Jedynym sposobem jest wykonanie tej operacji za pomocą „Disk Managera”. Prawy przycisk myszki na wolumenie i klikamy na shrink. Pamiętajmy o tym, aby nie zmniejszać przestrzeni o więcej, niż połowę za jednym razem. Co prawda nie jest to zabronione, ale z doświadczenia – gdy zmniejszamy za dużo, operacja się często nie udaje.
Jak skończymy, robimy „rescan” dysków w konsoli DPM (aby od razu wolne miejsce zostało dodane do niezaalokowanej przestrzeni).
Jest jeszcze kilka rzeczy, które mam nadzieję zostaną ulepszone takie jak shrinkowanie wielkosci repliki czy optymalizacja backupu na taśmy. Na chwilę obecną pozostaje nam czekać i mieć nadzieję, że te zmiany nastąpią.
Tommy.


 przykładowy scenariusz:
przykładowy scenariusz:
Hyper-v replication – Critical
Hv Replica jest dobrą ideą – jednak wykonanie szwanqje. wiele operacji, jakie jest wykonywane w ramach HvR jest zabójcze dla niego samego. do tego zachowanie jest bardzo nieprzejrzyste – do powodu błędów trzeba mocno dociekać, opisy są zwodnicze, braqje narzędzi do bezpośredniego debugowania. mówiąc w skrócie – mechanizm zaprojektowany jest jako samograj, a niestety jest na tyle niestabilny, że ciągle trzeba przy nim grzebać i jest to ciężka systemówka.
replikacja przerzuca pliki wektorów zmian [.hrl]. kiedy zostanie przerzucony plik, następuje… łączenie [merge] plików vhd. o ile w przypadq małej zmiany i małego pliq wszystko sobie działa dobrze, o tyle przewalenie kilq GB pliq do zmerdżowania z np. 1TB dyskiem, jest operacją zabijającą mechanizm – nie ma możliwości skończyć się ani w 5min [standardowy czas przerzucania zmian HvR] ani w 15min [max. jaki można ustawić] a zdarza się, że i godzina byłoby za mało, jeśli dyski są na prawdę duże. operacja jest wykonywana po stronie odbiorcy i jest to operacja bloqjąca – w czasie, kiedy jest wykonywana, z maszyną nie da się nic zrobić, a nadawca dostaje informację, że replikacji nie można wykonać.
dodatkowym problemem jest fakt, iż operacja łączenia dysków nie jest w żaden sposób pokazywana przez interfejs. błędy wyglądają następująco:
serwer wysyłający
log Hyper-V-VMMS/Admin, Event ID: 32552,
log Hyper-V-VMMS/Admin, Event ID: 32315,
serwer odbierający
log Hyper-V-VMMS/Admin, Event ID: 15268 [nie występuje zawsze]
log Hyper-V-VMMS/Storage, Event ID: 27000,
ponadto jest możliwość szybkiej weryfikacji przy pomocy PowerShell, weryfiqjąc status maszyny na serwerze odbierającym:
PS C:\scriptz\> get-vm <VMNAME>|select *status* OperationalStatus : {InService, ModifyingUpVirtualMachine} PrimaryOperationalStatus : InService SecondaryOperationalStatus : ModifyingUpVirtualMachine StatusDescriptions : {In service, Modifying virtual machine} PrimaryStatusDescription : In service SecondaryStatusDescription : Modifying virtual machine Status : Modifying virtual machine MemoryStatus :statusy wyraźnie pokazują – 'InService’ oraz 'ModifyingUpVirtualMachine’ – być może taki status jest również w innych scenariuszach, ale regularnie powtarzający się – może oznaczać tylko jedno. dyski się łączą.
dalsze konsekwencje
to za chwilę prowadzi to zmiany statusu repliki na 'critical’ i ustawienia wymuszenia resynchronizacji w następnym cyklu [standardowo chyba raz dziennie o 18.oo – godzinę można sobie ustawić]. jeśli ręcznie wymusi się powtórną próbę replikacji po zakończeniu operacji 'merge’, to wszystko powinno być ok i maszyna powinna się zacząć replikować. jeśli jednak zostawi się na automat, to do cyklu resync może minąć zbyt wiele czasu, a to będzie oznaczało faktyczny resync.
i tu dochodzimy do kolejnej maskrycznej operacji – resynchronizacja. jest to kolejna operacja bloqjąca, podczas trwania której sypią się backupy [lockowany jest VSS], a biorąc pod uwagą ile trwa czasu dla dużych dysqw, potrafi spowodować lawinowe błędy.
jak uniknąć części błędów
różnymi automatami – trzeba monitorować replikację i oskryptować całe rozwiązanie. można to zrobić w bardziej wyrafinowany sposób, można po prostu co jakiś czas wymuszać resync dla wszystkich maszyn.
jest też ciekawostka, która nigdzie nie jest opisana – w każdym razie nie trafiłem – podeślijcie linka, jeśli się mylę. póki co – wisienka na torcie, exclusive dla w-filesowiczów (;
kiedy poobserwuje się replikację, można zauważyć, że w pewnym momencie taski 'zawisają’. jeśli z powodów opisanych powyżej wykonuje się kilka resynchronizacji, nagle okazuje się, że pozostałe maszyny co i rusz, również wchodzą w stan 'critical’. ograniczeniem jest opcja definiująca ilość równoczesnych 'storage migration’, ustawiana we właściwościach Hyper-V. standardowo są to dwie operacje. nawet jeśli maszyny rozłożone są na kilq węzłach klastra, może okazać się, że jakieś dwie długie synchronizacje lub resynchronizacje, będą blokować pozostałe maszyny. dla tego warto ten parametr zwiększyć. to znacząco obniża ilość problemów!
ponoć w Windows 1o Server, mechanizm replikacji ma być wymieniony – ale również nie mogę znaleźć artykułu potwierdzającego ten fakt /:
będę wdzięczny za linki (:
eN.